Most popular activation functions for deep learning
Introduction
This page lists the most popular activation functions for deep learning. For each activation function, the following is described:
- equation of the function
- chart
- derivative,
- Python code
If you think an important activation function is missing, please contact me.
- Linear activation function
- Sigmoid activation function
- Hyperbolic tangent activation function
- Rectified Linear Unit Activation Function (ReLU)
- Leaky ReLU
- Parameterised ReLU
- Exponential Linear Unit (ELU)
Linear activation function
The linear (or identity) activation function is the simplest you can imagine the output copy the input.

The equation is:
$$ y = f(x) = x $$
This function is differentiable and monotonic.
The derivative is simply given by:
$$ y' = 1 $$
The Python code of the linear function is given by:
# Linear activation function
def linear_function(x):
return xThe Python code for the derivative is given by:
# Derivative of the linear activation function
def linear_derivative(x):
return [1] * len(x)Sigmoid activation function
The sigmoid (or logistic) activation function curve looks like a S-shape. The main advantage of the sigmoid is that the output is always in the range of 0 and 1:

The equation of the sigmoid is:
$$ y = \sigma(x) = \dfrac{1}{1 + e^{-x}} $$
This function is differentiable and monotonic.
The derivative is given by:
$$ y' = \dfrac{e^{-x}}{\left(1 + e^{-x}\right)^2} $$
The derivative of the sigmoid function can also be expressed with the sigmoid function:
$$ y' = \sigma(x) \cdot (1 - \sigma(x)) $$
The Python code of the sigmoid function is given by:
# Sigmoid activation function
def sigmoid_function(x):
return 1/(1+np.exp(-x))The Python code for the derivative is given by:
# Derivative of the sigmoid activation function
def sigmoid_derivative(x):
return np.exp(-x) / (1+ np.exp(-x))**2Hyperbolic tangent activation function
The hyperbolic tangent or tanh function is similar to the sigmoid function, but the range of tanh is of -1 and 1:

The equation of tanh is:
$$ y = \tanh(x) = \dfrac{ 1-e^ {-2x} }{1 + e^ {-2x}}$$
This function is differentiable and monotonic.
The derivative is given by:
$$ y' = 1- \dfrac { (e^x - e^{-x})^2 }{ (e^x + e^{-x})^2 } $$
The derivative of the tanh function can also be expressed with the tanh function:
$$ y' = 1-\tanh^2(x) $$
The Python code of the tanh function is given by:
# Tanh activation function
def tanh_function(x):
return np.tanh(x)The Python code for the derivative is given by:
# Derivative of the tanh activation function
def tanh_derivative(x):
return 1 - np.tanh(x)**2Rectified Linear Unit Activation Function (ReLU)
The ReLU is currently the most used activation function in convolutional neural networks.

The equation of the ReLU function is:
$$ y = \max(0,x) $$
The derivative is given by:
$$ y' = f(x)= \begin{cases} 0 & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
The derivative is undefined at x=0 (its left and right derivative are not equal).
The Python code of the ReLU function is given by:
# ReLU activation function
def ReLU_function(x):
return np.where(x <= 0, 0, x)The Python code for the derivative is given by:
# Derivative of the ReLU activation function
def ReLU_derivative(x):
return np.where(x <= 0, 0, 1)Leaky ReLU
The leaky ReLU is an improved version of the ReLU function. It has a small slope for negative values:

The equation of the leaky ReLU function is:
$$ y = f(x)= \begin{cases} 0.01x & \text{if } x < 0 \\ x & \text{if } x > 0 \\ \end{cases} $$
The derivative is given by:
$$ y' = f(x)= \begin{cases} 0.01 & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
As for the ReLU activation fonction, the derivative is undefined at x=0 (its left and right derivative are not equal).
The Python code of the leaky ReLU function is given by:
# Leaky ReLU activation function
def leakyReLU_function(x):
return np.where(x <= 0, 0.01*x, x)The Python code for the derivative is given by:
# Derivative of the leaky ReLU activation function
def leakyReLU_derivative(x):
return np.where(x <= 0, 0.01, 1)Parameterised ReLU
The parameterised ReLU is another variant of the ReLU function, very similar to the leaky ReLU. The parameterised ReLU introduces a new parameter as a slope of the negative part of the function.
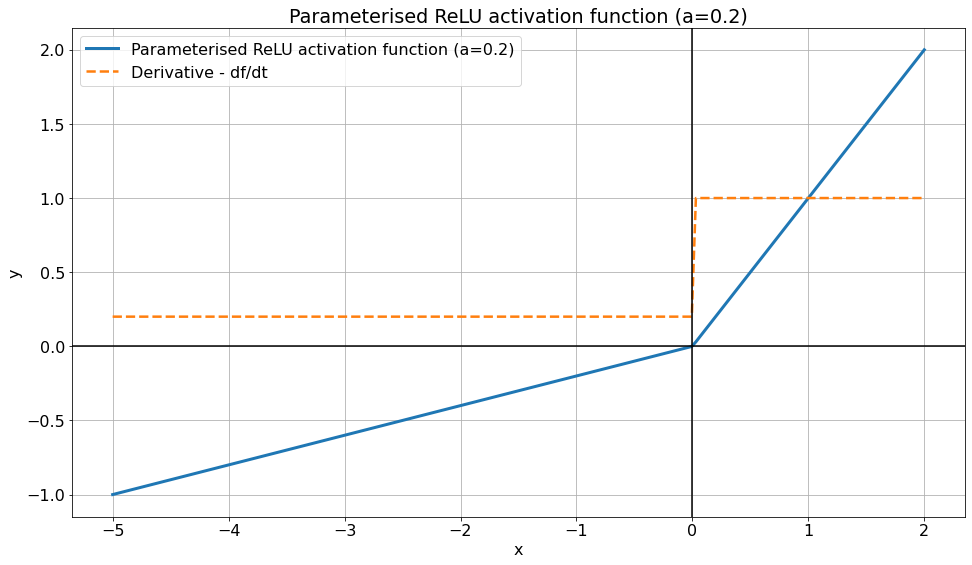
When the value of \(a\) is equal to 0.01, the function acts as a Leaky ReLU function.
The equation of the parameterised ReLU function is:
$$ y = f(x)= \begin{cases} ax & \text{if } x < 0 \\ x & \text{if } x > 0 \\ \end{cases} $$
Where \( a \) is a trainable parameter. The derivative is given by:
$$ y' = f(x)= \begin{cases} a & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
As for the ReLU activation fonction, the derivative is undefined at x=0 (its left and right derivative are not equal).
The Python code of the parameterised ReLU function is given by:
# Parameterised ReLU activation function
def parameterised_ReLU_function(x,a):
return np.where(x <= 0, a*x, x)The Python code for the derivative is given by:
# Derivative of the parameterised ReLU activation function
def parameterised_ReLU_derivative(x,a):
return np.where(x <= 0, a, 1)Exponential Linear Unit (ELU)
Exponential Linear Unit is another variant of the ReLU function. The ELU activation function uses a log curve for the negative part of the function:

ELU was first proposed in this paper.
The equation of the ELU function is:
$$ y = f(x)= \begin{cases} \alpha(e^x -1) & \text{if } x < 0 \\ x & \text{if } x > 0 \\ \end{cases} $$
Where \( \alpha \) is a trainable parameter.
The derivative is given by:
$$ y' = f(x)= \begin{cases} \alpha.e^x & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
When the value of \( \alpha \) is equal to 1, the function is diferentiable.
The derivative of the ELU function can also be expressed with the ELU function:
$$ y' = f(x)= \begin{cases} f(x) + \alpha & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
The Python code of the ELU function is given by:
# ELU activation function
def ELU_function(x,a):
return np.where(x <= 0, a*(np.exp(x) - 1), x)The Python code for the derivative is given by:
# Derivative of the ELU activation function
def ELU_derivative(x,a):
return np.where(x <= 0, a*np.exp(x), 1)Download
- Google Colab used for creating the figures.
- Jupyter notebook with Python source code.
- Python source code.
See also
- Neural networks curve fitting
- Datasets for deep learning
- Gradient descent example
- How popular are neural networks over the years?
- Install TensorFlow and Keras for Linux
- Learning rule demonstration
- Linear regression example
- Most relevant deep learning research papers
- Neural Network Perceptron
- Simplest neural network with TensorFlow
- Simplest perceptron
- Single layer training algorithm
- Single layer classification example
- Gradient descent for neural networks
- Single layer limitations
- Neural networks