Single layer limitations
This page presents with a simple example the main limitation of single layer neural networks.
Network architecture
Let's consider the following single-layer network architecture with two inputs ( \(a, b \) ) and one output ( \(y\) ).

Logic OR function
Let's assume we want to train an artificial single-layer neural network to learn logic functions. Let's start with the OR logic function:
| a | b | y = a + b |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 1 |
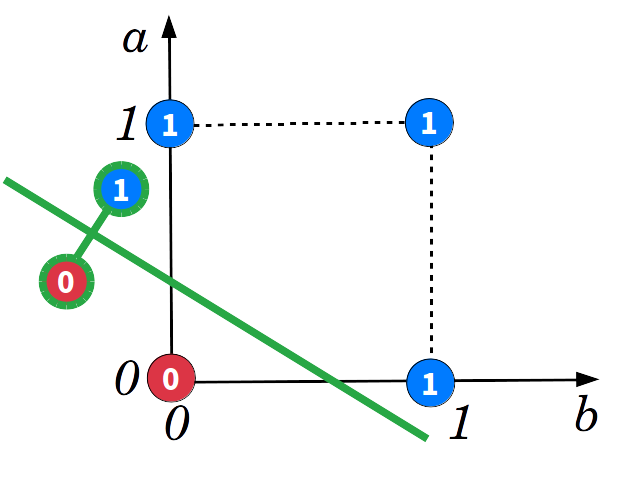
The space of the OR fonction can be drawn. X-axis and Y-axis are respectively the \( a \) and \( b\) inputs. The green line is the separation line ( \( y=0 \) ). As illustrated below, the network can find an optimal solution:
Logic XOR function
Assume we now want to train the network on the XOR logic function:
| a | b | y = a ⊕ b |
|---|---|---|
| 0 | 0 | 0 |
| 0 | 1 | 1 |
| 1 | 0 | 1 |
| 1 | 1 | 0 |
As for the OR function, space can be drawn. Unfortunatly, the network isn't able to disriminate ones from zeros.

Conclusion
The transfert function of this single-layer network is given by:
$$ \begin{equation} y= w_1a + w_2b +w_3 \label{eq:transfert-function} \end{equation} $$
The equation \( \eqref{eq:transfert-function} \) is a linear model. This explain why the frontier between ones and zeros is necessary a line. The XOR function is a non-linear problem that can't be classified with a linear model. Fortunatly, multilayer perceptron (MLP) can deal with non-linear problems.
See also
- Neural networks curve fitting
- Datasets for deep learning
- Gradient descent example
- How popular are neural networks over the years?
- Install TensorFlow and Keras for Linux
- Learning rule demonstration
- Linear regression example
- Most popular activation functions for deep learning
- Most relevant deep learning research papers
- Neural Network Perceptron
- Simplest neural network with TensorFlow
- Simplest perceptron
- Single layer training algorithm
- Single layer classification example
- Gradient descent for neural networks
- Neural networks