Modélisation du Coronavirus pour la Chine continentale
Cette page présente une modéliation et son optimisation pour l'évolution du COVID-19 pour la Chine continentale. Cette modélisation s'appuie sur les données temps-réelles de l'université Johns Hopkins
Données
Cette modélisation s'appuie sur les données temps-réelles de l'université Johns Hopkins Voici les données dans le script Python :
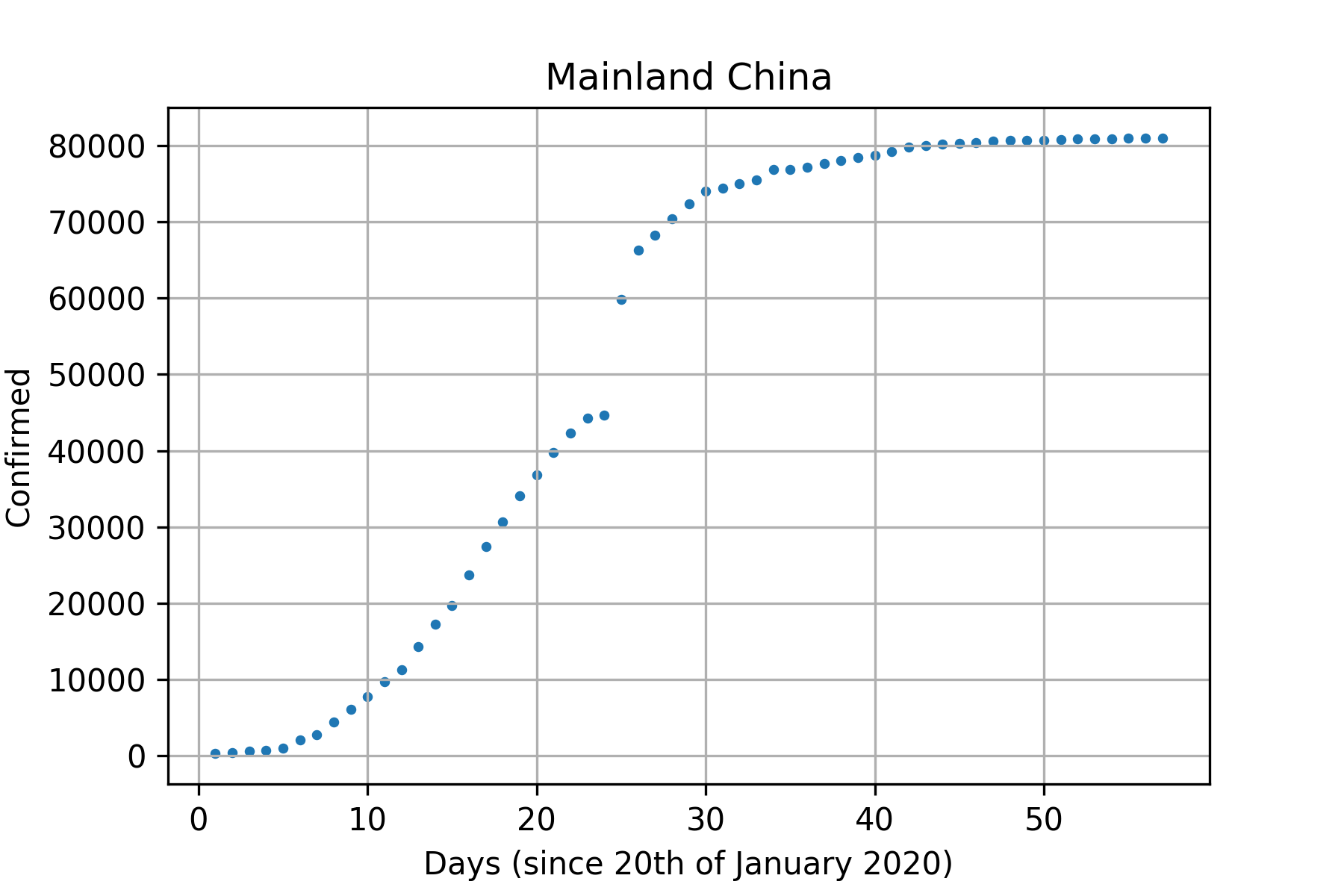
yChina = np.array([278, 326, 547, 639, 916, 2000, 2700, 4400, 6000, 7700, 9700, 11200, 14300, 17200, 19700, 23700, 27400, 30600, 34100, 36800, 39800, 42300, 44300, 44700, 59800, 66300, 68300, 70400, 72400, 74100, 74500, 75000, 75500, 76900, 76900, 77200, 77700, 78100, 78500, 78800, 79300, 79800, 80000, 80200, 80300, 80400, 80600, 80700, 80700, 80700, 80800, 80900, 80900, 80900, 81000, 81000, 81000])
xChina = np.linspace(1, yChina.size, yChina.size)
plt.scatter(xChina, yChina, s=5)
plt.title('Mainland China')
plt.xlabel('Days (since 20th of January 2020)')
plt.ylabel('Confirmed')
plt.grid()
plt.show()Nos données de référence sous forme de graphique :
Modèle
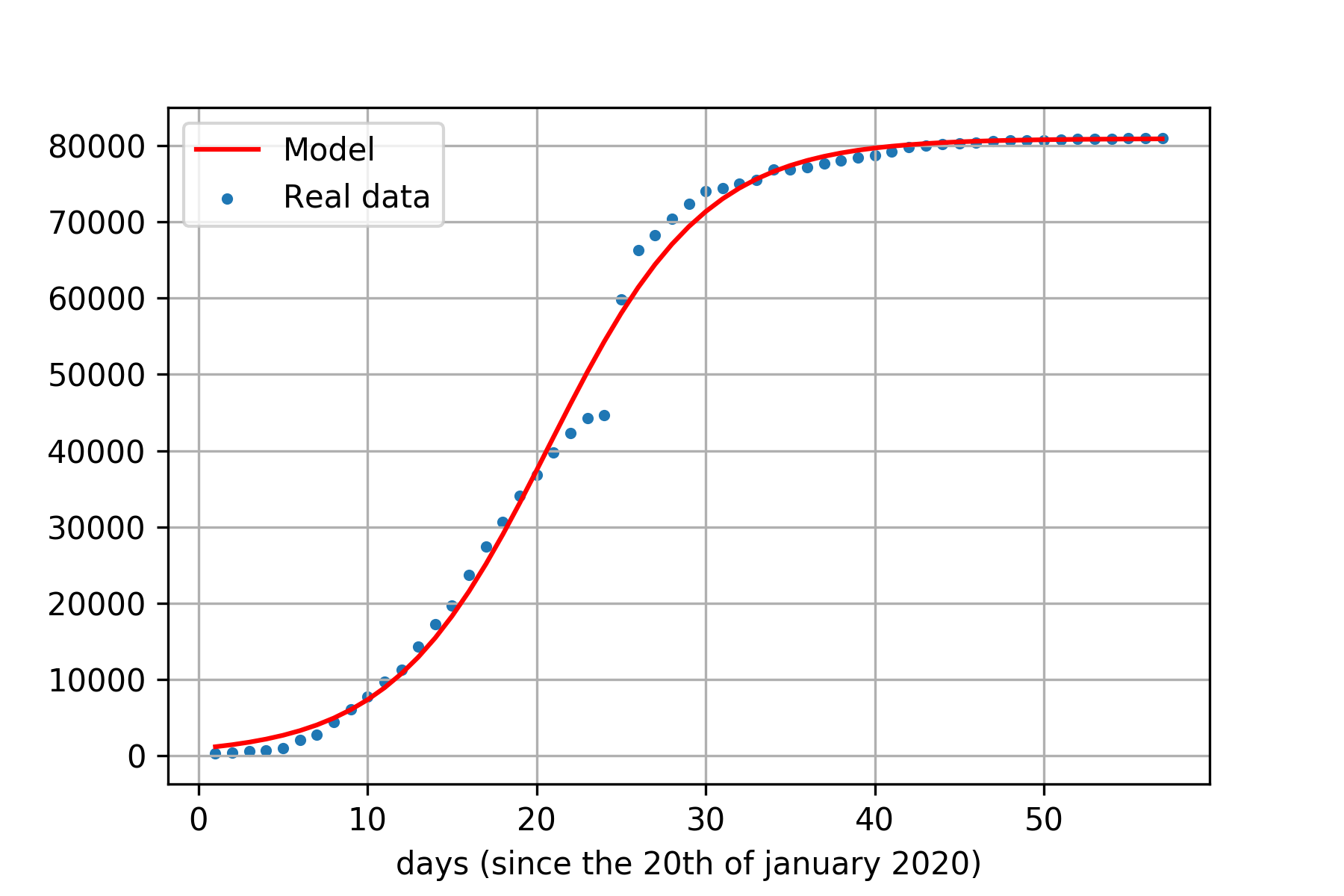
Cette modélisation s'appuie sur l'hypothèse que le virus suit une propagation régie par une loi exponentielle. Notre modèle sera une sigmoïde :
Considérons le modèle suivant :
$$ y = \frac { \lambda } { 1 + e^{-\alpha(x-n)} } $$
avec:
- \( \lambda \) le nombre de cas confirmés au pique de l'épidémie
- \( \alpha \) re présente la vitesse de propagation du virus
- \( n \) est le nombre de jours depuis la première donnée (le 20 jnavier 2020)
def model(x, lam, alpha, n):
return lam / (1 + exp(-alpha*(x-n)))Notre but est ici d'estimer les paramètres afin que l'erreur entre le modèle et les données réelles soit le plus faible possible.
Optimisation
L'optimisation s'appuie sur LMFIT (Non-Linear Least-Squares Minimization and Curve-Fitting) pour Python.
Voici le code utilisé pour l'optimisation :
gmodel = Model(model)
params = gmodel.make_params(lam=81000, alpha=0.2, n=20)
result = gmodel.fit(yChina, x=xChina, lam=40000, alpha=0.2, n=10)Voici les résultats d'optimisation, les paramètres estimés sont :
- \( \lambda = 80954.3863 \pm 490.839259 ( 0.61 \% ) \)
- \( \alpha = 0.21600181 \pm 0.00662431 ( 3.07 \% ) \)
- \( n = 20.6996270 \pm 0.16547593 ( 0.80 \% ) \)
Testez et exécutez le code source sur Google Colabory.
Voir aussi
- Prédiction de l'évolution du Coronavirus
- Prédiction de l'évolution du nombre de décès liés au COVID-19 dans différents pays
- Prédiction de l'évolution du COVID-19 dans différents pays