Jeux de données pour l'apprentissage profond
Cette page liste quelques-un des datasets utilisés pour l'apprentissage profond, les réseaux de neurones, la classification ... Je la mets à jour régulièrement.
Je suis actuellement à la recherche de dataset de traduction, si vous en connaissez (de bonne qualité) qui ne sont pas listés ici, n'hésitez pas à me contacter.
Si vous trouvez un lien érroné ou une erreur sur la page, là encore, n'hésitez pas à me contacter.
Natural images
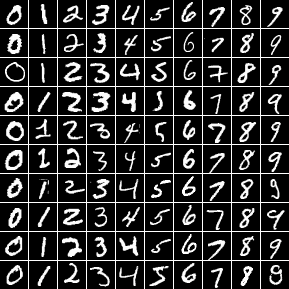
MNIST database
Base de données de caractères écrits à la main, jeu de données de 60 000 exemples pour l'apprentissage et 10 000 pour le test.

NIST Special Database 19
Base de données de document et caractères manuscrits pour la reconnaissance de caractères. Ce jeu contient 800 000 images classifées et vérifiées à la main.

The CIFAR-10 dataset
60 000 image couleur de 32x32 pixels classifiées dans 10 classes (avion, chat, oiseau, camion...) avec 6 000 images par classe (50 000 images d'entrainement et 10 000 images de test).

Caltech 101
Images d'objets appartenant à 101 categories. De 40 à 800 images par categorie d'approximativement 300 x 200 pixels.

Caltech 256
Photos d'objets appartenant à 101 categories.
Texte
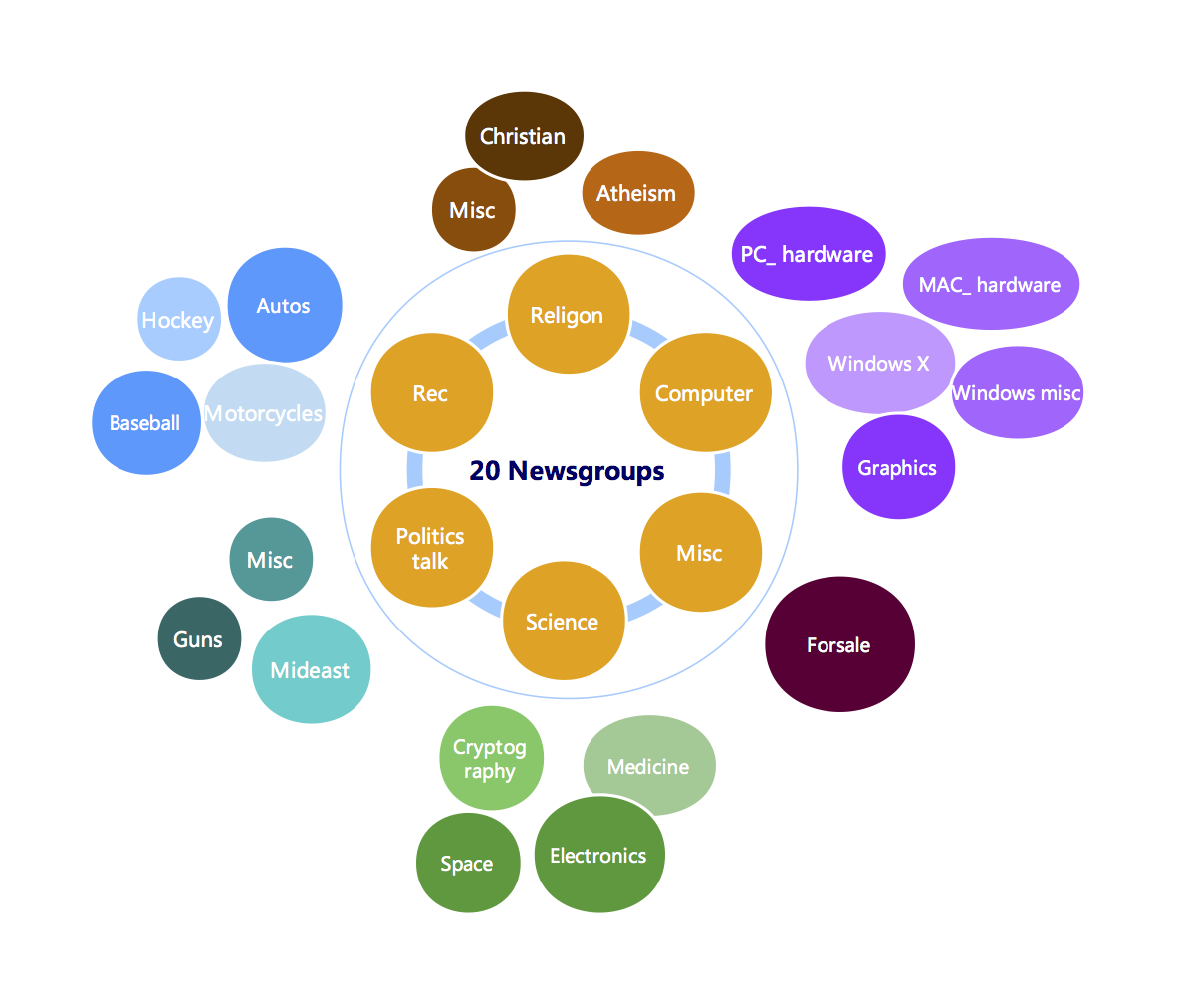
Collection d'environ 20 000 documents de newsgroups, partitionnés partitioned (nearly) evenly across 20 different newsgroups.
a large collection of Reuters News stories for use in research and development of natural language processing, information retrieval, and machine learning systems.

Fournit l'annotation sémantique et le sens des prédicats pour environ 50 000 prédicats, correspondant à tous les verbes, tous les adjectifs dans les clauses équationnelles et tous les noms considérés comme prédicatifs.
Contient plus de 1,8 million d'articles écrits et publiés par le New York Times entre le 1er janvier 1987 et le 19 juin 2007.
Contient les n-grams des mots anglais et leur nombre de fréquences observées. La longueur des n-grams va de unigrammes (mots simples) à 5-grams.

Wikipedia met à disposition des copies de tous ses contenus.
Voir aussi
- Régression non linéaire avec un réseau de neurones
- Exemple de descente de gradient
- Quelle est la popularité des réseaux de neurones dans le temps ?
- Installation de TensorFlow et Keras sous Linux
- Démonstration de la règle d'apprentissage
- Exemple en régression linéaire
- Fonctions d'activation les plus utilisées en apprentissage profond
- Principaux papiers de recherches relatif au Deep learning
- Le perceptron dans les réseaux de neurones
- Le réseau de neurones le plus simple avec TensorFlow
- Perceptron simpliste
- Algorithme d'apprentissage pour réseaux sans couches cachées
- Exemple de classification
- Descente de gradient pour les réseaux de neurones
- Limitations des réseaux sans couches cachées
- Réseaux de neurones