Fonctions d'activation les plus utilisées en apprentissage profond
Introduction
Cette page décrit les fonctions d'activations les plus populaires en apprentissage profond. Pour chaque fonction d'activation, sont présentés :
- l'équation de la fonction
- le graphique de la fonction
- sa dérivée
- Le code Python de cette fonction
Si vous pensez que d'autres fonctions d'activations sont manquantes, contactez moi !
- Fonction d'activation linéaire
- Fonction d'activation sigmoïde
- Tangente hyperbolique
- Rectified Linear Unit Activation Function (ReLU)
- Leaky ReLU
- ReLU paramétrique
- Unité exponentielle linéaire (ELU)
Fonction d'activation linéaire
La fonction d'activation linéaire (ou identité) est la plus simple que l'on puisse imaginer, elle recopie l'entrée sur la sortie
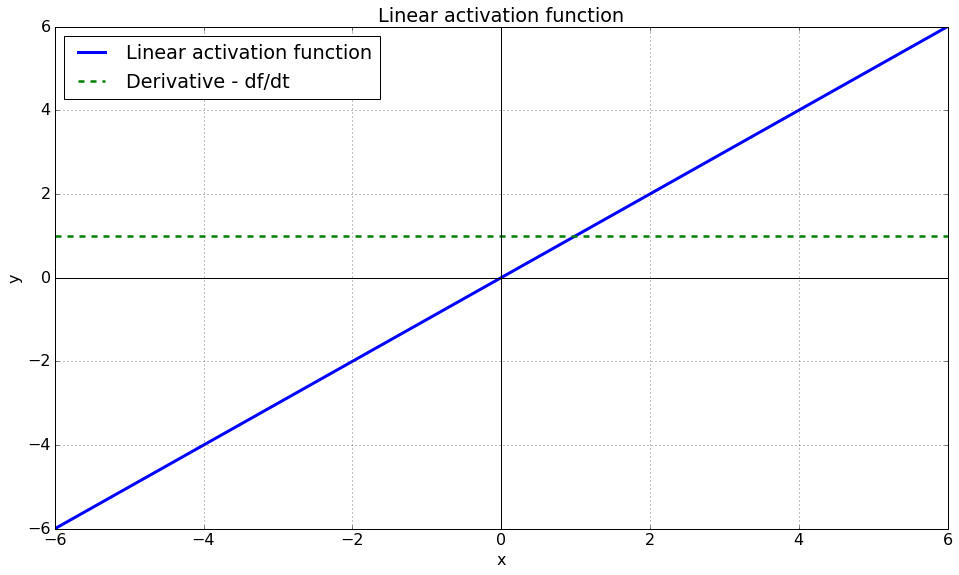
L'équation est :
$$ y = f(x) = x $$
Cette fonction est différentiable et monotone.
La dérivée est dimplement donnée par :
$$ y' = 1 $$
Le code Python pour la fonction d'activation linéaire est :
# Fonction d'activation linéaire
def linear_function(x):
return xLe code Python pour la fonction dérivée est donné ci-dessous :
## Dérivée de la fonctoin d'activation linéaire
def linear_derivative(x):
return [1] * len(x)Fonction d'activation sigmoïde
La fonction sigmoïde (ou logistique) est une fonction d'activation dont la coube ressemble à un S. L'avantage principale de la fonction sigmoïde est que sa sortie est toujours comprise entre 0 et 1 :

M'équation de la fonction sigmoïde est donnée par :
$$ y = \sigma(x) = \dfrac{1}{1 + e^{-x}} $$
Cette fonction est différentiable et monotone.
La dérivée est donnée par :
$$ y' = \dfrac{e^{-x}}{\left(1 + e^{-x}\right)^2} $$
La dérivée de la fonction sigmoïde peut aussi être exprimée en fonction de la fonction sigmoïde :
$$ y' = \sigma(x) \cdot (1 - \sigma(x)) $$
Voici une implémentation de la fonction sigmoïde en Python :
# Fonction d'activation sigmoïde
def sigmoid_function(x):
return 1/(1+np.exp(-x))Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation sigmoïde
def sigmoid_derivative(x):
return np.exp(-x) / (1+ np.exp(-x))**2Tangente hyperbolique
La tangente hyperbolique (ou fonction tanh) est similaire à la fonction sigmoïde, mais la fonction est comprise entre -1 et 1 :

L'équation de la tangente hyperbolique est donnée par :
$$ y = \tanh(x) = \dfrac{ 1-e^ {-2x} }{1 + e^ {-2x}}$$
Cette fonction est différentiable et monotone.
La dérivée est donnée par :
$$ y' = 1- \dfrac { (e^x - e^{-x})^2 }{ (e^x + e^{-x})^2 } $$
La dérivée de la fonction tanh peut aussi être exprimée en fonction de la fonction tanh :
$$ y' = 1-\tanh^2(x) $$
Voici une implémentation de la fonction tanh en Python :
# Fonction d'activation tanh
def tanh_function(x):
return np.tanh(x)Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation tanh
def tanh_derivative(x):
return 1 - np.tanh(x)**2Rectified Linear Unit Activation Function (ReLU)
La fonction ReLU esta ctuellement la fonction al plus utilisée dans les réseau neuronaux convolutif.

L'équation de la fonction ReLU est donnée par :
$$ y = \max(0,x) $$
Ladérivée est donnée par:
$$ y' = f(x)= \begin{cases} 0 & \text{si } x < 0 \\ 1 & \text{si } x > 0 \\ \end{cases} $$
La dérivée n'est pas définie en x=0 (Les dérivées à droite et à gauche sont différentes).
Voici une implémentation de la fonction ReLU en Python :
# Fonction d'activation ReLU
def ReLU_function(x):
return np.where(x <= 0, 0, x)Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation ReLU
def ReLU_derivative(x):
return np.where(x <= 0, 0, 1)Leaky ReLU
La fonction leaky ReLU est une amélioration de la fonction ReLU function. La différence est qu'elle a une légére pente négative dans les valeurs négatives :

L'equation de la fonction leaky ReLU est :
$$ y = f(x)= \begin{cases} 0.01x & \text{si } x < 0 \\ x & \text{si } x > 0 \\ \end{cases} $$
La dérivée est donnée par :
$$ y' = f(x)= \begin{cases} 0.01 & \text{si } x < 0 \\ 1 & \text{si } x > 0 \\ \end{cases} $$
Comme pour la fonction ReLU, la dérivée n'est pas définie en x=0 (Les dérivées à droite et à gauche sont différentes).
Voici une implémentation de la fonction leaky ReLU en Python :
# Fonction d'activation leaky ReLU
def leakyReLU_function(x):
return np.where(x <= 0, 0.01*x, x)Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation leaky ReLU
def leakyReLU_derivative(x):
return np.where(x <= 0, 0.01, 1)ReLU paramétrique
La fonction ReLU paramétrique est un autre variant de la fonction ReLU, très similaire à la fonction leaky ReLU. La fonction ReLU paramétrique introduit un nouveau paramètre qui représente la pente pour les valeur négative de \(x\).
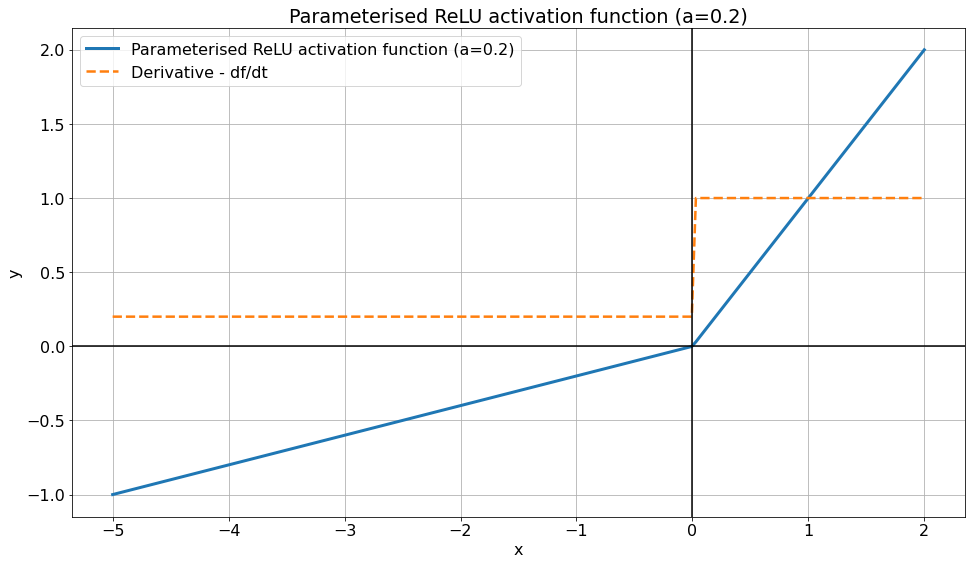
Lorsque la valeur de \(a\) est égale à 0.01, la fonction est une Leaky ReLU.
L'equation de la fonction ReLU paramétrique est donnée par :
$$ y = f(x)= \begin{cases} ax & \text{si } x < 0 \\ x & \text{si } x > 0 \\ \end{cases} $$
Où \( a \) est un paramètre entraînable.
La dérivée est donnée par :
$$ y' = f(x)= \begin{cases} a & \text{if } x < 0 \\ 1 & \text{if } x > 0 \\ \end{cases} $$
Comme pour la fonction ReLU, la dérivée n'est pas définie en x=0 (Les dérivées à droite et à gauche sont différentes).
Voici une implémentation de la fonction ReLU paramétrique en Python :
# Fonction d'activation ReLU paramétrique
def parameterised_ReLU_function(x,a):
return np.where(x <= 0, a*x, x)Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation ReLU paramétrique
def parameterised_ReLU_derivative(x,a):
return np.where(x <= 0, a, 1)Unité exponentielle linéaire (ELU)
L'unité exponentielle linéaire (ELU - Exponential Linear Unit) est un autre variation de la fonction ReLU. La fonction ELU utilise une courbe logarithmique pour la partie négative de la fonction :

La fonction d'activation ELU a été proposée pour la première fois dans ce papier.
L'équation de la fonction d'activaiton ELU est donnée par :
$$ y = f(x)= \begin{cases} \alpha(e^x -1) & \text{if } x < 0 \\ x & \text{if } x > 0 \\ \end{cases} $$
Où \( \alpha \) est un paramètre entraînable.
La dérivée est donnée par :
$$ y' = f(x)= \begin{cases} \alpha.e^x & \text{si } x < 0 \\ 1 & \text{si } x > 0 \\ \end{cases} $$
Lorsque \( \alpha = 1\), la fonction est dérivable.
La dérivée de la fonction ELU peut aussi être exprimée en fonction de la la fonction ELU elle-même :
$$ y' = f(x)= \begin{cases} f(x) + \alpha & \text{si } x < 0 \\ 1 & \text{si } x > 0 \\ \end{cases} $$
Voici une implémentation de la fonction ELU paramétrique en Python :
# La fonction d'activaiton ELU
def ELU_function(x,a):
return np.where(x <= 0, a*(np.exp(x) - 1), x)Voici une implémentation de la dérivée en Python :
# Dérivée de la fonction d'activation ELU
def ELU_derivative(x,a):
return np.where(x <= 0, a*np.exp(x), 1)Téléchargement
- Google Colab pour la création des figures pour chaque fonction.
- Code source Python / Jupyter notebook.
- Code source Python.
Voir aussi
- Régression non linéaire avec un réseau de neurones
- Jeux de données pour l'apprentissage profond
- Exemple de descente de gradient
- Quelle est la popularité des réseaux de neurones dans le temps ?
- Installation de TensorFlow et Keras sous Linux
- Démonstration de la règle d'apprentissage
- Exemple en régression linéaire
- Principaux papiers de recherches relatif au Deep learning
- Le perceptron dans les réseaux de neurones
- Le réseau de neurones le plus simple avec TensorFlow
- Perceptron simpliste
- Algorithme d'apprentissage pour réseaux sans couches cachées
- Exemple de classification
- Descente de gradient pour les réseaux de neurones
- Limitations des réseaux sans couches cachées
- Réseaux de neurones