Régression non linéaire avec un réseau de neurones
Cette page présente un exemple d'approximation d'une courbe à l'aide d'un réseau de neurones. Cet exemple montre et détaille comment résoudre un problème de régression non linéaire avec TensorFlow.
La suite de cette page a été réalisée avec les versions suivantes :
- Python 3.6.9 64 bits
- Matplotlib 3.1.1
- TensorFlow 2.1.0
Vous pouvez essayer l'exemple en ligne sur Google Colaboratory.
Définition du problème
Le but de cet exemple est d'approximer une fonction non linéaire donnée par l'équation suivante :
$$ y = 0.1.x.\cos(x) $$
Les points bleus représente un échantillon de notre jeu d'apprentissage, la ligne rouge est l'approximation faite par le réseau de neurones artificiel :
Code source
Chaque ligne est expliquée dans la section suivante. Cet exemple peut aussi être exécuté en ligne sur Google Colaboratory
Explications
Commençons par importer les bibliothèques nécessaires :
- numpy pour les tableaux et les matrices
- matplotlib pour afficher les graphiques
- google.colab pour télécharger les fichiers (seulement si vous utilisez Google Colaboratory)
- Tensorflow pour les réseaux de neurones
- math pour la fonction cosinus
import numpy as np
import matplotlib.pyplot as plt
from tensorflow import keras
from google.colab import files
import tensorflow as tf
import mathEnsuite, créons le jeu de données pour l'apprentissage. x_data est composé de 1000 points,
et un bruit normal est ajouté sur l'axe des ordonnées pour haque point :
# Create noisy data
x_data = np.linspace(-10, 10, num=1000)
y_data = 0.1*x_data*np.cos(x_data) + 0.1*np.random.normal(size=1000)
print('Data created successfully')
Voici le jeu de données utilisé pour l'apprentissage :
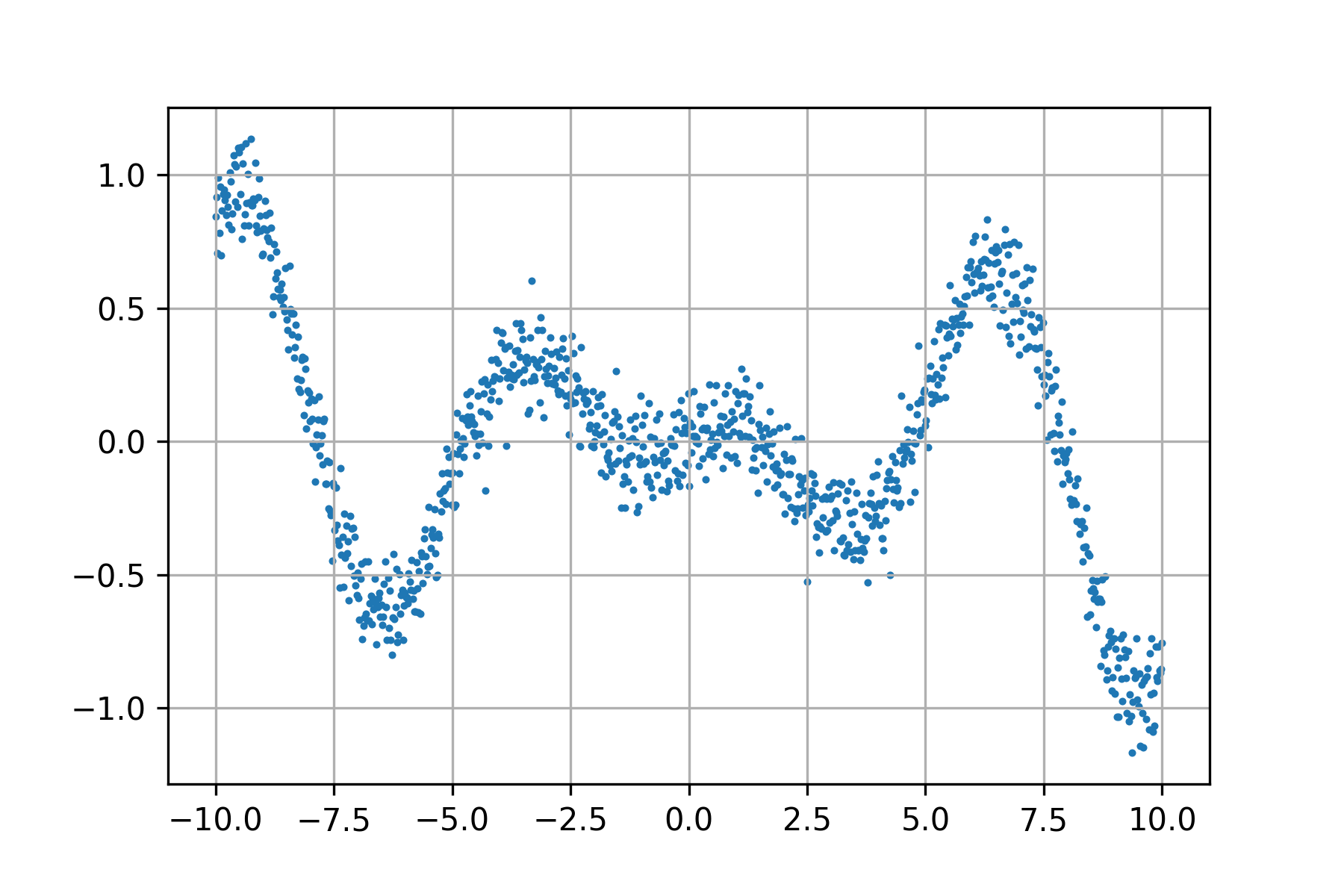
Lorsque notre jeu de données est prêt, nous pouvons créer le réseau :
- La première couche contient un seul neurone linéaire (pour l'entrée)
- La seconde couche contient 64 unité de type RELU
- La troisième couche contient 64 unité de type RELU
- La dernière couche ne contient qu'une unité linéaire (pour la sortie)
RELU n'est probablement pas le meilleur choix pour cette application, mais ça fonctionne quand même correctement. ELU devrait produire une courbe moins dicontinue.
# Create the model
model = keras.Sequential()
model.add(keras.layers.Dense(units = 1, activation = 'linear', input_shape=[1]))
model.add(keras.layers.Dense(units = 64, activation = 'relu'))
model.add(keras.layers.Dense(units = 64, activation = 'relu'))
model.add(keras.layers.Dense(units = 1, activation = 'linear'))
model.compile(loss='mse', optimizer="adam")
# Display the model
model.summary()Le modèle est compilé avec les paramètre d'optimisation suivants:
- L'algorithme d'optimisation est Adam (
optimizer="adam"), plus d'info sur cette page - Loss est la perte ou l'erreur calculée sur la base des moindres carrés (
loss='mse'). Plus d'informations sur les metriques ici
Une fois le modèle créé, entraînons notre réseau :
x_dataest l'entréey_dataest la sortie désiréeepochs=5signifie que notre réseaux sera entrainé 5 fois sur notre jeu de donnéesverbose=1affiche la progression dans la console
# Training
model.fit( x_data, y_data, epochs=100, verbose=1)La ligne ci-dessus devrait afficher quelque chose comme (loss doit diminuer au fil de l'apprentissage) :
Train on 1000 samples
Epoch 1/100
1000/1000 [==============================] - 0s 321us/sample - loss: 0.2125
Epoch 2/100
1000/1000 [==============================] - 0s 49us/sample - loss: 0.1914
Epoch 3/100
1000/1000 [==============================] - 0s 50us/sample - loss: 0.1932
Epoch 4/100
1000/1000 [==============================] - 0s 60us/sample - loss: 0.1922
...
Epoch 97/100
1000/1000 [==============================] - 0s 59us/sample - loss: 0.0180
Epoch 98/100
1000/1000 [==============================] - 0s 53us/sample - loss: 0.0188
Epoch 99/100
1000/1000 [==============================] - 0s 54us/sample - loss: 0.0161
Epoch 100/100
1000/1000 [==============================] - 0s 55us/sample - loss: 0.0147Lorsque l'apprentissage est terminé, nous pouvons prédire l'approximation :
# Compute the output
y_predicted = model.predict(x_data)
# Display the result
plt.scatter(x_data[::1], y_data[::1])
plt.plot(x_data, y_predicted, 'r', linewidth=4)
plt.grid()
plt.show()Voici le résultat :

Source code
Vous pouvez tester cet exemple en ligne sur Google Colaboratory
Voir aussi
- Jeux de données pour l'apprentissage profond
- Exemple de descente de gradient
- Quelle est la popularité des réseaux de neurones dans le temps ?
- Installation de TensorFlow et Keras sous Linux
- Démonstration de la règle d'apprentissage
- Exemple en régression linéaire
- Fonctions d'activation les plus utilisées en apprentissage profond
- Principaux papiers de recherches relatif au Deep learning
- Le perceptron dans les réseaux de neurones
- Le réseau de neurones le plus simple avec TensorFlow
- Perceptron simpliste
- Algorithme d'apprentissage pour réseaux sans couches cachées
- Exemple de classification
- Descente de gradient pour les réseaux de neurones
- Limitations des réseaux sans couches cachées
- Réseaux de neurones