Descente de gradient pour les réseaux de neurones
La majorité des réseaux de neurones artificiels s'appuie sur l'algoritme de descente de gradient. Il est indispensable de comprendre les fondements de cet algorithme avant d'étudier les réseaux de neurones à proprement parlé. La descente de gradient est un algorithme d'optimisation permettant de trouver le minimum d'une fonction.
Principe
Considérons la fonction dérivable \(f(x)\) que l'on souhaite minimier. L'algorithme de descente de gradient démarre à une coordonnée initiale arbitraire et converge vers le minimum de façon itérative, comme illustré ci-dessous:

Nommons \(x_0\) le point de départ de l'algorithme. Pour déterminer le point suivant \(x_1\), la descente de gradient calcule la dérivée \(f′(x_o)\), comme illustré sur cette figure:

La dérivée etant la pente de la tangeante en ce point, elle est généralement un bon indicateur de la distance entre ce point et le minimum. Le point suivant est alors calculé grâce à la formule suivante:
$$ x_{n+1} = x_n - \alpha.\frac{df}{dx}(x_n) $$
où :
- \( x_{n+1} \) est le point suivant
- \( x_{n} \) est le point courant
- \( \alpha \) est le pas de l'algorithme (step size multiplier)
Pas de l'algorithme
Le pas de l'algorithne \( \alpha \) est un paramètre à régler. Il représente la taille des pas entre deux itérations. Le dilemne caché derrière ce paramètre est qu'il permet une convergence rapide pour un pas élevé, mais de petites valeurs assurent plus de stabilité à l'algorithme. Sur l'illustration ci-dessous, un pas trop grand empèche l'algorithme de converger vers le minimum:

Il est à noter que ce paramètre de s'appelle plus le pas ( \( \alpha \ ) dans les réseaux de neurones articiels, mais le facteur d'apprentissage ( \( \eta \) ), learning rate en anglais.
Optimisation multidimensionelle
Pour plus de clareté, l'algorithme a été présenté sur une fonction unidimensionelle ( \( f: \mathbb{R} \mapsto \mathbb{R} \) ). Les principes exposés précédemment peuvent être étendus à des fonctions multidimensionelles ( \( f: \mathbb{R}^n \mapsto \mathbb{R} \) ). La dérivée est alors remplacé par le gradient de la fonction. C'est la raison pour laquelle cet algorithme s'appelle la descente du gradient. La généralisation multidimensionelle de l'algorithme de descente de gradient est donnée par l'équation suivante:
$$ X_{n+1} = X_n - \alpha\nabla f(X_n) $$
où:
\( X{n+1} \) est le point suivant dans \( \mathbb{R}^n \) \( X{n} \) est le point actuel dans \( \mathbb{R}^n \) \( \alpha \) est le pas de l'algorithme \( \nabla f(X_n) \) est le gradient de la fonction \( f \) localement exprimé au point \( X_n \)
Le gradient est donné par:
$$ \nabla f(X) = \begin{pmatrix} \frac{df}{dx_1} \\ \frac{df}{dx_2} \\ \vdots \\ \frac{df}{dx_n} \end{pmatrix} $$
La figure ci-dessous (issue du blog de Hoang Duong) illustre la convergence de l'algorithme sur un problème multidimensionnel:

Minima locaux
Lors de l'utilisation de la descente de gradient, il faut considérer le fait que l'algorithme peut converger vers des minimas locaux, comme illustré ci-dessous:
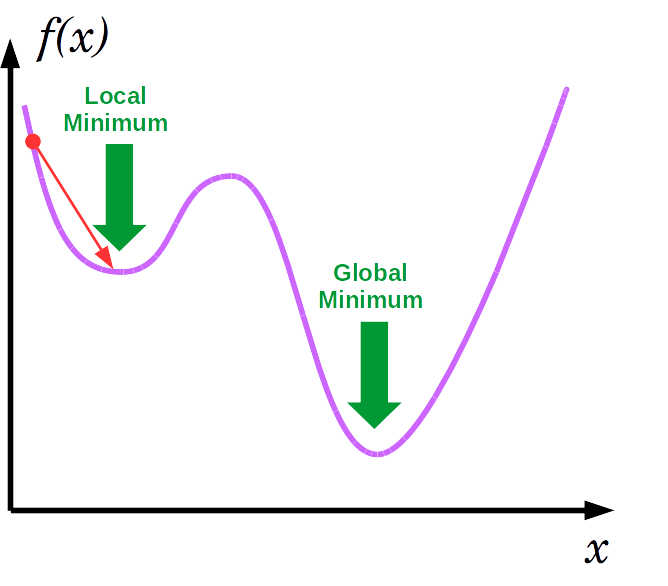
Lorsque cet algorithme est utilisé pour l'optimation des paramètres d'un réseaux de neurones, cette limitation peut empécher le réseaux de converger correctement. Heureusement, en pratique nous travaillons avec des modèles ayant un grand nombre de paramètres. Généralement, le minima local dans une dimension n'est pas partagé avec les autres dimensions. cela explique pourquoi les réseaux de neurones peuvent être utilisés sur des problèmes complexes, mais cela explique aussi pourquoi il est si difficile d'obtenir des preuves de convergence.
Voir aussi
- Régression non linéaire avec un réseau de neurones
- Jeux de données pour l'apprentissage profond
- Exemple de descente de gradient
- Quelle est la popularité des réseaux de neurones dans le temps ?
- Installation de TensorFlow et Keras sous Linux
- Démonstration de la règle d'apprentissage
- Exemple en régression linéaire
- Fonctions d'activation les plus utilisées en apprentissage profond
- Principaux papiers de recherches relatif au Deep learning
- Le perceptron dans les réseaux de neurones
- Le réseau de neurones le plus simple avec TensorFlow
- Perceptron simpliste
- Algorithme d'apprentissage pour réseaux sans couches cachées
- Exemple de classification
- Limitations des réseaux sans couches cachées
- Réseaux de neurones