Algorithme d'apprentissage pour réseaux sans couches cachées
Network architecture
Considérons l'architecture sans couche cachée suivante :
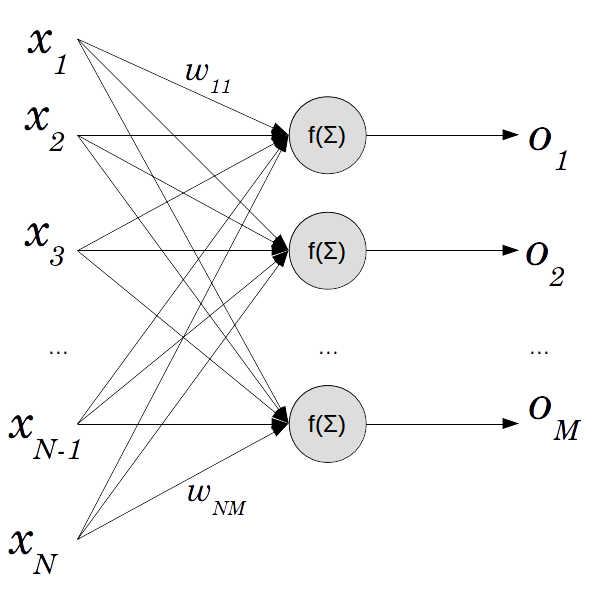
where:
- \(x_i\) sont les entrées du réseau
- \(o_j\) sont les sorties du réseau
- \(f(\sigma)\) est la fonction d'activation
- \(w_{ij}\) est le poids connecté entre l'entrée \(x_i\) et le neurone \(j\) (c-a-d associé à la sortie \(o_j\))
Algorithme
Voici l'algorithme d'entraînement pour des réseaux sans couche cachée :
Initialiser les poids \( w_{ij} \) avec une valeur arbitraire
Répéter
Choisir un exemple dans la base d'entrainement <\( x \),\( \check{o}\)> (x est l'entrée, \( \check{o} \) est la sortie désirée)
Calculer la somme de chaque neurone : \( S_j = \sum\limits_{i=1}^N w_{ij}x_i \)
alculer les sorties (\( o \)) du réseau : \( o_j = f(S) \)
Pour chaque sortie, calculer l'erreur : \( \delta_j = ( \check{o}_j - o_j ) \)
Actualiser les poids synaptiques : \( w_{ij} = w_{ij} + \eta.\delta_j.x_i.\frac{df(S)}{dS} \)
Tant qu'il reste des exemples
Voir aussi
- Régression non linéaire avec un réseau de neurones
- Jeux de données pour l'apprentissage profond
- Exemple de descente de gradient
- Quelle est la popularité des réseaux de neurones dans le temps ?
- Installation de TensorFlow et Keras sous Linux
- Démonstration de la règle d'apprentissage
- Exemple en régression linéaire
- Fonctions d'activation les plus utilisées en apprentissage profond
- Principaux papiers de recherches relatif au Deep learning
- Le perceptron dans les réseaux de neurones
- Le réseau de neurones le plus simple avec TensorFlow
- Perceptron simpliste
- Exemple de classification
- Descente de gradient pour les réseaux de neurones
- Limitations des réseaux sans couches cachées
- Réseaux de neurones
Dernière mise à jour : 11/03/2020